Wortsuche im Millisekunden-Takt
Unsere Fähigkeit zu Sprechen beruht auf einem mehrstufigen Hochgeschwindigkeitsprozeß im Gehirn, belegen niederländische Max-Planck-Wissenschaftler
Sprachproduktion ist das Ergebnis zweier sehr schnell ablaufender Vorgänge im Gehirn, dem Abruf geeigneter Einträge aus einem „mentalen Lexikon“ sowie der Vorbereitung dieser „Einträge“ für das eigentliche Sprechen, berichten Wissenschaftler vom Max-Planck-Institut für Psycholinguistik in Nijmegen/Niederlande in der neuen Ausgabe der renommierten Fachzeitschrift „Proceedings of the National Academy of Sciences“ (PNAS, 98, 23, 6. November 2001).
Jeder Mensch lernt Sprechen und das bedeutet vor allem: Wörter zu produzieren. Wächst er in der westlichen Kultur auf, hat er als Erwachsener bereits bis zu 50 Millionen Wörter gesprochen. Es gibt kaum eine andere Tätigkeit, die wir so oft praktizieren. Bei einer Unterhaltung liegt die durchschnittliche Sprechgeschwindigkeit bei zwei bis vier Wörtern pro Sekunde. Die Wörter dazu werden fortlaufend aus unserem „mentalen Lexikon“ abgerufen, das mehrere zehntausend „Einträge“ enthält. Bei diesem Vorgang machen wir erstaunlich wenig Fehler (und sagen z.B. „links“ statt „rechts“). Durchschnittlich passiert uns das nicht mehr als einmal pro Tausend Wörter. Doch wie ist dieser so robuste und schnelle Sprachmechanismus organisiert?
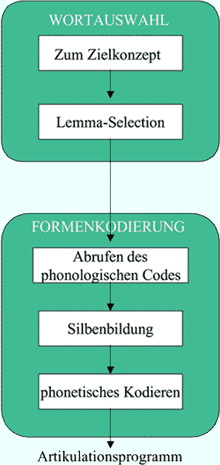
Wissenschaftler erklären die Sprachproduktion als ein System zweier aufeinanderfolgender Verarbeitungsschritte (s. Abb.). Im ersten Schritt erfolgt die Wortauswahl: Erhält das Gehirn einen bestimmten inhaltlichen Reiz, z.B. von den visuellen Zentren, wählt es einen dazu passenden lexikalischen Eintrag aus dem mentalen Lexikon. Der zweiten Schritt behandelt die Formenkodierung und berechnet die artikulatorischen Gesten, die für die Aussprache des Zielwortes benötigt werden. Es ist der Forschergruppe um Prof. Willem Levelt, Dr. Antje Meyer und Dr. Ardi Roelofs in langjähriger Teamarbeit gelungen, das Modell experimentell zu bestätigen; Dr. Roelofs konnte diese Theorie in einem umfassenden Computerprogramm mit dem Namen „WEAVER++“ umsetzen.
Ein wichtiges experimentelles Verfahren zur Erforschung des lexikalischen Zugriffs im Gehirn ist das Benennen von Bildern. Auf dem Monitor erscheint ein Bild, z.B. ein Pferd, das die Versuchsperson so schnell wie möglich benennen soll. Hierbei wird die Reaktionszeit, d.h. die Zeit zwischen dem Erscheinen des Bildes und dem Beginn des Sprechens exakt gemessen. Diese liegt normalerweise bei 600 Millisekunden (ms). Für die Auswahl und Aussprache eines Wortes brauchen wir also weniger als zwei Drittel einer Sekunde.
Die Wortauswahl selbst erfolgt in zwei Teilstufen: Zuerst wird das Bild erkannt und ein Zielkonzept für die Benennungsaufgabe selektiert. Die Tests können so gesteuert werden, dass die Versuchspersonen entweder „Pferd“, „Tier“ oder „Hengst“ auswählen, um das Bild zu benennen. In der zweiten Stufe, der so genannten „Lemma-Selektion“, wird der hiermit übereinstimmende Eintrag gewählt, also z.B. nur „Pferd“. Diesen Eintrag nennt man „Lemma“, was soviel bedeutet wie „syntaktisches Wort“, d.h. es enthält alle syntaktischen Eigenschaften wie Wortklasse (Substantiv, Verb usw.) und syntaktische Merkmale (wie Geschlecht bei Substantiven, transitive Beschaffenheit bei Verben). Diese Wortauswahl erfolgt in Konkurrenz zu anderen Wörtern. Die Max-Planck-Wissenschaftler konnten messen, dass semantisch verwandte Wörter, wie „Tier“ oder „Hengst“, bei diesem Schritt ebenfalls aktiviert werden.
Mit Hilfe der quantitativen Computertheorie wird die Reaktionszeit für eine Wortauswahl unter Konkurrenz vorausgesagt. Überprüft werden diese Voraussagen in spezifischen Bildbenennungsexperimenten: Dabei werden den Versuchspersonen beim Bildbenennen – visuell oder akustisch – andere Wörter präsentiert. Diesen Ablenkungsreiz müssen sie ignorieren. Ist beispielsweise „Pferd“ das Zielwort, reagiert die Versuchsperson beim Hören des damit nicht verwandten Wortes „Stuhl“ etwas langsamer. Hört die Versuchsperson jedoch das semantisch verwandte Wort „Kuh“, wird eine viel stärkere Verzögerung gemessen, zusätzlich etwa 50 bis 100 Millisekunden (je nach Rahmenbedingungen). Diesen „semantischen Verzögerungseffekt“ fanden die Max-Planck-Wissenschaftler in einer Vielzahl von Experimenten bestätigt.
Der Zeitverlauf der Lemma-Selektion wurde außerdem gemeinsam mit Wissenschaftlern am Max-Planck-Institut für neuropsychologische Forschung in Leipzig mit Hilfe der Magnetenzephalographie (MEG) gemessen und bestätigt. Hierbei fanden die Max-Planck-Forscher außerdem heraus, dass bei der Lemma-Auswahl Regionen im linken lateralen temporalen Lobus aktiv sind.
Nach der Lemma-Selektion erfolgt der zweite Schritt, die Wortformplanung oder Wordformen-Kodierung. Dazu muss zuerst der phonologische Code abgerufen werden, d.h. eine Reihe phonologischer „Segmente“ oder „Phoneme“, z.B. “ p, f, e, r, d“. Bei geläufigen Wörtern wird der phonologische Code schneller (bis zu 40 Millisekunden ) abgerufen als bei selten benutzten Wörtern. Bei der Bildbenennung kann der Zugriff dadurch erleichtert werden, dass der Versuchsperson zeitgleich phonologisch verwandte Wörter präsentiert werden. Versuchspersonen nennen „Pferd“ schneller, wenn sie während der Bildanbietung das phonologisch verwandte Wort „Pfeil“ hören, als das phonologisch unterschiedliche Wort „Stuhl“. Auch den Zeitverlauf dieser phonologischen Suche konnten die Wissenschaftler mit dem Computermodell „WEAVER++“ exakt voraussagen.
Ist das Abrufen des Codes aus dem mentalen Lexikon abgeschlossen, erfolgt die Silbenbildung. Diese wird Phonem für Phonem zusammengestellt, aus „p, f, e, r, d“ zum Beispiel wird /pfert/. Wird das Zielwort jedoch im Plural benötigt (z.B. wenn zwei Pferde auf dem Bild zu sehen sind), werden nacheinander zwei Silben – /pfer/–/de/ – gebildet. Anders gesagt, ob die Silbe „/pfert/“ oder „/pfer/“ gebildet wird, ist situationsbedingt. Das schrittweise Zusammenstellen der Silben dauert etwa 25 Millisekunden pro Phonem. Sind mehrsilbige Wörter zu bilden, verändert sich die Reaktionszeit: Testpersonen brauchten beim Benennen für mehrsilbige Wörter länger als für einsilbige.
Die letzte Stufe der Wortformen-Kodierung ist das phonetische Kodieren, das Abrufen eines artikulatorisch-motorischen Programms für jede neugebildete Silbe. Die Max-Planck-Wissenschaftler nehmen an, dass dazu ein mentaler Silbenvorrat existiert, ein „Lager“ an Gesten oder motorischen Programmen für häufig benutzte Silben. Die Vermutung liegt nahe, dass beim Speichern häufig gebrauchter Silben der prämotorische Cortex/die Broca Area beteiligt ist. Die faktische Ausführung der aufeinanderfolgenden Silbenprogramme vom laryngealen und supralaryngealen Artikulationssytem generiert letztendlich das gesprochene Wort
Weitere Informationen erhalten Sie von:
Prof. Willem J.M. Levelt
Max-Planck-Institut für Psycholinguistik, Nijmegen/Niederlande
Tel.: +31 / 24 / 35 21 – 3 17
Fax: +31 / 24 / 35 21 – 2 13
E-Mail: pim@mpi.nl
Media Contact
Weitere Informationen:
http://www.mpg.de/pri01/pri0168.pdfAlle Nachrichten aus der Kategorie: Interdisziplinäre Forschung
Aktuelle Meldungen und Entwicklungen aus fächer- und disziplinenübergreifender Forschung.
Der innovations-report bietet Ihnen hierzu interessante Berichte und Artikel, unter anderem zu den Teilbereichen: Mikrosystemforschung, Emotionsforschung, Zukunftsforschung und Stratosphärenforschung.

Neueste Beiträge

Diamantstaub leuchtet hell in Magnetresonanztomographie
Mögliche Alternative zum weit verbreiteten Kontrastmittel Gadolinium. Eine unerwartete Entdeckung machte eine Wissenschaftlerin des Max-Planck-Instituts für Intelligente Systeme in Stuttgart: Nanometerkleine Diamantpartikel, die eigentlich für einen ganz anderen Zweck bestimmt…
Neue Spule für 7-Tesla MRT | Kopf und Hals gleichzeitig darstellen
Die Magnetresonanztomographie (MRT) ermöglicht detaillierte Einblicke in den Körper. Vor allem die Ultrahochfeld-Bildgebung mit Magnetfeldstärken von 7 Tesla und höher macht feinste anatomische Strukturen und funktionelle Prozesse sichtbar. Doch alleine…

Hybrid-Energiespeichersystem für moderne Energienetze
Projekt HyFlow: Leistungsfähiges, nachhaltiges und kostengünstiges Hybrid-Energiespeichersystem für moderne Energienetze. In drei Jahren Forschungsarbeit hat das Konsortium des EU-Projekts HyFlow ein extrem leistungsfähiges, nachhaltiges und kostengünstiges Hybrid-Energiespeichersystem entwickelt, das einen…

