Deep Learning für die Texterschließung
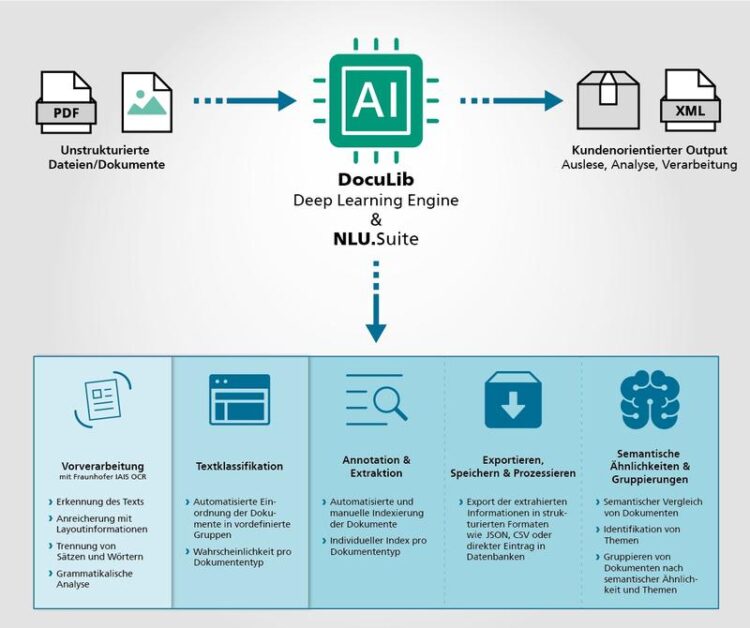
The Fraunhofer IAIS DocuLib solution and the NLU.Suite facilitate end-to-end text and document analysis – from OCR to understanding the text with the aid of artificial intelligence.
© Fraunhofer IAIS
Dokumente schneller analysieren mit Künstlicher Intelligenz von Fraunhofer
Die Flut von Dokumenten, die in Wirtschaft und Gesellschaft täglich entsteht, stellt eine enorme Herausforderung dar. Informationen aus zahlreichen unterschiedlichen Quellen müssen sortiert, verarbeitet und bewertet werden. Betroffen davon sind Unternehmen, aber auch Behörden, Forschungseinrichtungen und Krankenhäuser. Das Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS hat Lösungen entwickelt, die Dokumente aller Art klassifizieren und die Textinhalte erschließen. Den Schlüssel bilden dabei KI-basierte Sprachmodelle, die mit Deep-Learning-Verfahren trainiert werden.
E-Mails, Aufträge, Lieferscheine, Angebote, Verträge, Reports – täglich entstehen im Geschäftsleben neue Daten und Dokumente. Nur, wenn es gelingt, diese Informationsflut sinnvoll zu strukturieren, können Unternehmen die richtigen Entscheidungen treffen und schnell agieren. Das gilt auch für öffentliche Einrichtungen wie Behörden, Bibliotheken, Forschungseinrichtungen oder Krankenhäuser. Das Fraunhofer IAIS hat hierfür eine mehrteilige End-to-End-Lösung entwickelt: Die »DocuLib« und die »NLU Suite« sind KI-basierte Software-Lösungen, mit denen sich Dokumente aller Art nahezu automatisch digitalisieren, einordnen und inhaltlich erschließen lassen.
DocuLib – OCR-Software mit Deep-Learning-Technologie
Wenn noch Papierdokumente vorhanden sind, werden diese eingescannt und durch die DocuLib, eine OCR-Software (Optical Character Recognition), erfasst. Die Texterkennung arbeitet mit Deep-Learning-Modellen, die von den Expertinnen und Experten des Fraunhofer IAIS entwickelt wurden und in internationalen Benchmarks regelmäßig vorne liegen. Damit erkennt die Software auch schlecht lesbare Buchstaben auf vergilbtem oder rissigem Papier. Ein gemusterter Hintergrund, beispielsweise auf Fahrkarten, ist ebenfalls kein Problem.
Die Lösungen des Fraunhofer IAIS zur Dokumentenanalyse ermöglichen auch die schnelle Erschließung der digitalisierten oder schon in digitaler Form vorliegenden Dokumente. Sie klassifizieren Dokumente beispielsweise als Rechnung, Reisebeleg, Flugticket oder E-Mail. Zudem extrahieren sie Basisinformationen wie Namen, Daten oder Zahlen. Auch längere Dokumente wie Briefe oder Gutachten lassen sich erschließen und so miteinander verknüpfen. Überall da, wo viele Dokumente anfallen, spart das viel Zeit. Die Software kann etwa Eingangspost sortieren und automatisch an den zuständigen Ansprechpartner weiterleiten.
Dr. Nicolas Flores-Herr, Geschäftsfeldleiter Document Analytics am Fraunhofer IAIS, sagt: »Unser Ziel ist es, mit Hilfe von Künstlicher Intelligenz die Informationsverarbeitung weitgehend zu automatisieren. Hierdurch werden bei unseren Kunden sämtliche dokumentenbasierte Arbeitsprozesse beschleunigt.« Für Unternehmen, die Software für Dokumentenmanagement oder Enterprise Content Management installiert haben, sind die Software-Lösungen des Fraunhofer IAIS eine ideale Ergänzung. Sie sind marktreif, im Einsatz bei Unternehmen etabliert und werden von den Fraunhofer-Forschenden kontinuierlich weiterentwickelt.
Sprachmodelle zur inhaltlichen Texterschließung
Noch einen Schritt weiter geht es beim Natural Language Understanding (NLU). Die NLU-Lösungen sind in der Lage, komplexe, unstrukturierte Dokumente inhaltlich zu erschließen. Für die semantische Textanalyse hat das NLU-Team Sprachmodelle entwickelt, die mit Deep-Learning-Verfahren trainiert werden. Die Sprachmodelle werden zunächst mit Tausenden Texten aus verschiedenen Themenfeldern gefüttert. Darunter auch Zeitungsartikel, Social Media-Postings oder E-Mails. Damit baut das KI-Modul ein statistisches Modell auf. Im zweiten Schritt greift der Mensch ein und gibt Regeln für die zielgerichtete Auswertung vor. »Durch die Kombination von Statistik und Regeln benötigt die Software weniger Daten, gleichzeitig arbeitet sie schneller und präziser«, sagt Sven Giesselbach, Teamleiter Natural Language Understanding am Fraunhofer IAIS.
Die NLU-Suite analysiert Dokumente, extrahiert Eckdaten und erstellt bei Bedarf sogar eine strukturierte Zusammenfassung. Mit diesen Ergebnissen, aber auch über den Inhalt der Dokumente selbst, lassen sich Dokumente vergleichen oder Texte mit ähnlichen Informationen finden. Stehen in einem Text A beispielsweise die Begriffe »Diebstahl« und »Kette« und in Text B die Begriffe »Schmuck« und »gestohlen«, erkennt das Sprachmodell die thematische Verwandtschaft. Und die Software versteht auch, dass der Satz »Die Rate wird im Voraus am Anfang des Monats fällig.« in Dokument A eine ähnliche Bedeutung hat wie »Die Rate ist monatlich vorschüssig zu zahlen.« in Dokument B.
»Unsere KI-basierten Sprachmodelle sind der klassischen Verschlagwortung deutlich überlegen. Denn sie finden nicht nur Texte mit vordefinierten Schlagwörtern, sondern suchen intelligent nach Begriffen, die in ähnlichem Zusammenhang auftauchen oder als Synonym gebraucht werden. Außerdem reagiert die Software auch auf morphologische Ähnlichkeiten«, erklärt Giesselbach. Ein konkretes Anwendungsbeispiel sind etwa Gerichtsurteile. Die IAIS-Expertinnen und Experten arbeiten dabei mit der juristischen Fakultät der Universität Köln zusammen. Hier sucht die NLU-Suite beispielsweise selbstständig Urteile heraus, die durch Merkmale wie ähnliches Strafmaß oder ähnlichen Tathergang auffallen. So werden inhaltliche Übereinstimmungen zwischen unterschiedlichen Dokumenten sichtbar.
In Krankenhäusern kann die NLU-Lösung medizinische Diagnosen oder Arztbriefe auswerten. Bei einem neu auftauchenden Fachbegriff wie etwa »Covid-19« würde die KI-Software erkennen, dass in dessen Kontext überdurchschnittlich häufig das Wort »Lunge« steht und könnte dementsprechend Dokumente finden, die sich mit Atemwegserkrankungen beschäftigen. Der Datenschutz ist dabei jederzeit gewährleistet. Alle personenbezogenen Daten werden anonymisiert und die Server stehen in Deutschland. Zugleich werden die Bestimmungen der Datenschutz-Grundverordnung (DSGVO) eingehalten.
Fremdsprachige Dokumente
Darüber hinaus beherrschen die NLU-Sprachmodelle auch fremdsprachige Texte und analysieren in einem Arbeitsgang sowohl englische als auch deutsche Dokumente. Giesselbach und sein Team entwickeln die Deep-Learning-Sprachmodelle ständig weiter. So erkennt das System positive oder negative Bewertungen in Texten und ist in einigen Domänen wie der Automobilbranche auch in der Lage, die Emotionen von Verfassern zu erkennen.
Für die Nutzer ist die komplexe Struktur der NLU-Suite nicht spürbar. Die Anwendung läuft auf normalen Desktop-Rechnern. Nur für die Erstellung und das Training des Sprachmodells ist leistungsstarke Hardware erforderlich. Bereits einsatzbereite NLU-Anwendungen sind die Auswertung von Gerichtsurteilen, Reisebelegen und Leasingverträgen. Im Healthcare-Bereich sind Anwendungen wie etwa die Auswertung von medizinischer Fachliteratur und der Analyse klinischer Dokumente einsatzbereit.
Weitere Informationen:
https://www.fraunhofer.de/de/presse/presseinformationen/2020/september/dokumente…
Media Contact
Alle Nachrichten aus der Kategorie: Informationstechnologie
Neuerungen und Entwicklungen auf den Gebieten der Informations- und Datenverarbeitung sowie der dafür benötigten Hardware finden Sie hier zusammengefasst.
Unter anderem erhalten Sie Informationen aus den Teilbereichen: IT-Dienstleistungen, IT-Architektur, IT-Management und Telekommunikation.




Neueste Beiträge

Neues Wirkprinzip gegen Tuberkulose
Gemeinsam ist es Forschenden der Heinrich-Heine-Universität Düsseldorf (HHU) und der Universität Duisburg-Essen (UDE) gelungen, eine Gruppe von Molekülen zu identifizieren und zu synthetisieren, die auf neue Art und Weise gegen…

Gefahr durch Weltraumschrott
Neue Ausgabe von „Physikkonkret“ beleuchtet Herausforderungen und Lösungen für eine nachhaltige Nutzung des Weltraums. Die Deutsche Physikalische Gesellschaft (DPG) veröffentlicht eine neue Ausgabe ihrer Publikationsreihe „Physikkonkret“ mit dem Titel „Weltraumschrott:…

Wasserstoff: Versuchsanlage macht Elektrolyseur und Wärmepumpe gemeinsam effizient
Die nachhaltige Energiewirtschaft wartet auf den grünen Wasserstoff. Neben Importen braucht es auch effiziente, also kostengünstige heimische Elektrolyseure, die aus grünem Strom Wasserstoff erzeugen und die Nebenprodukte Sauerstoff und Wärme…

